L'IA générative étant une passion, je suis constamment à la recherche de nouveaux outils pour améliorer la pertinence et la flexibilité des systèmes de question-réponse basés sur les grands modèles de langage (LLM). Récemment, j'ai découvert la bibliothèque RAG Anything, un projet open source qui propose une approche modulaire et extensible du Retrieval-Augmented Generation (RAG). Dans ce billet, je vous propose de découvrir cette bibliothèque, ses atouts, et comment l'utiliser pour concevoir des pipelines RAG sur-mesure, tout en partageant quelques astuces de prompt engineering.
Qu'est-ce que RAG Anything ?
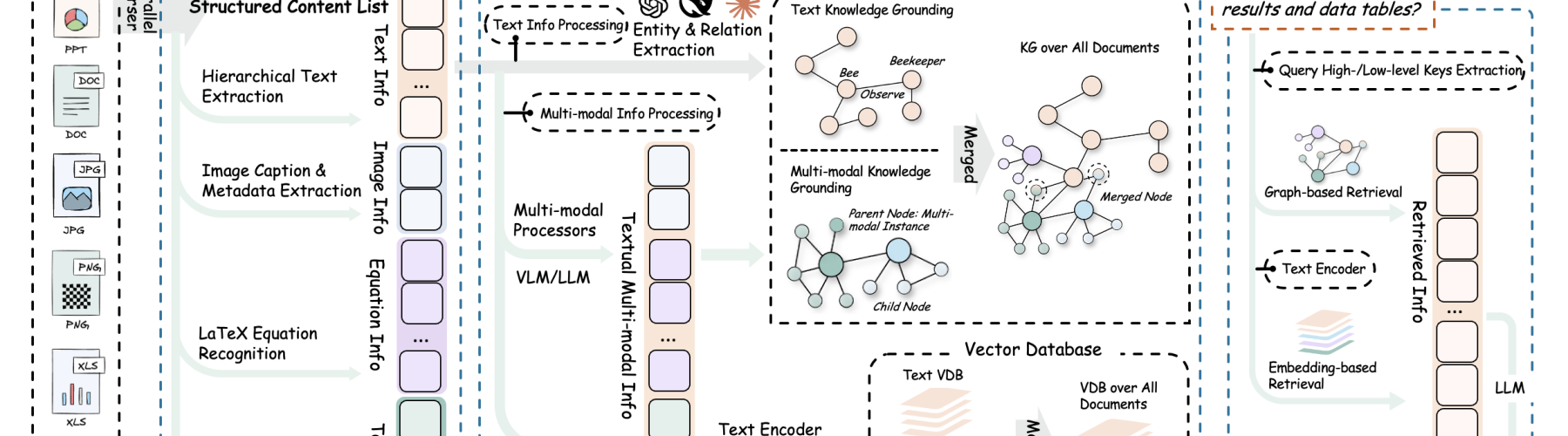
RAG Anything est une bibliothèque Python qui vise à démocratiser et simplifier la création de pipelines RAG. Pour rappel, le RAG consiste à combiner la puissance des LLM avec des modules de recherche documentaire, afin d’augmenter la qualité et la véracité des réponses générées. Là où de nombreux frameworks imposent des architectures rigides, RAG Anything se distingue par sa flexibilité : chaque composant du pipeline (loader, splitter, embedder, retriever, reranker, LLM, etc.) peut être choisi, combiné, remplacé ou personnalisé selon les besoins.
La philosophie de RAG Anything est de permettre à chacun de construire son propre pipeline, en piochant dans une large bibliothèque de modules prêts à l’emploi, ou en intégrant ses propres briques. Cela ouvre la voie à des expérimentations avancées en prompt engineering, en retrieval, ou en reranking, pour optimiser la pertinence des réponses.
Installation et premiers pas
L’installation de RAG Anything est très simple. Il suffit de cloner le dépôt GitHub et d’installer les dépendances :
git clone https://github.com/HKUDS/RAG-Anything.git
cd RAG-Anything
pip install -r requirements.txt
La bibliothèque propose une interface en ligne de commande (rag-anything) et une API Python. Pour les besoins du prompt engineering, l’API Python offre une grande souplesse.
Voici un exemple minimaliste de pipeline RAG avec RAG Anything, utilisant un loader de fichiers texte, un splitter par paragraphes, un embedder basé sur Sentence Transformers, un retriever FAISS, et un LLM OpenAI :
from rag_anything.pipeline import RAGPipeline
from rag_anything.loaders import TextFileLoader
from rag_anything.splitters import ParagraphSplitter
from rag_anything.embedders import SentenceTransformerEmbedder
from rag_anything.retrievers import FaissRetriever
from rag_anything.llms import OpenAILLM
# Chargement des documents
loader = TextFileLoader("data/mon_corpus.txt")
documents = loader.load()
# Découpage en paragraphes
splitter = ParagraphSplitter()
chunks = splitter.split(documents)
# Embedding
embedder = SentenceTransformerEmbedder(model_name="all-MiniLM-L6-v2")
embeddings = embedder.embed(chunks)
# Indexation et retrieval
retriever = FaissRetriever()
retriever.build_index(embeddings, chunks)
# LLM
llm = OpenAILLM(api_key="sk-...")
# Pipeline RAG
pipeline = RAGPipeline(
retriever=retriever,
llm=llm
)
# Question utilisateur
question = "Quels sont les avantages du RAG ?"
result = pipeline.answer(question)
print(result)
Ce code illustre la modularité de RAG Anything : chaque composant peut être remplacé par un autre, ou personnalisé.
Prompt engineering et personnalisation du pipeline
L’un des points forts de RAG Anything est la possibilité de personnaliser le prompt envoyé au LLM, en fonction des documents récupérés. Cela permet d’expérimenter différentes stratégies de prompt engineering pour maximiser la pertinence des réponses.
Par exemple, on peut injecter les documents récupérés dans un template de prompt, en ajoutant des instructions spécifiques :
from rag_anything.prompts import PromptTemplate
template = PromptTemplate(
"Voici des extraits de documents :\n{context}\n\nEn vous appuyant uniquement sur ces extraits, répondez à la question suivante :\n{question}\nRéponse :"
)
pipeline = RAGPipeline(
retriever=retriever,
llm=llm,
prompt_template=template
)
question = "Expliquez le concept de RAG en IA."
result = pipeline.answer(question)
print(result)
On peut également jouer sur le nombre de documents injectés, leur ordre, ou leur formatage (par exemple, en ajoutant des titres, des sources, ou des résumés). RAG Anything permet de chaîner plusieurs modules de reranking, de filtering, ou de post-processing, pour affiner encore le pipeline.
Exemples avancés : multi-retrieval, reranking et hybridation
RAG Anything ne se limite pas à un schéma retrieval + LLM. Il est possible de combiner plusieurs retrieveurs (par exemple, dense + lexical), d’ajouter des modules de reranking (BM25, Cross-Encoder, etc.), ou d’hybrider les sources de données.
Voici un exemple de pipeline hybride, combinant un retriever dense (FAISS) et un retriever lexical (BM25), puis fusionnant les résultats avant de les envoyer au LLM :
from rag_anything.retrievers import BM25Retriever, HybridRetriever
# Retriever lexical
bm25_retriever = BM25Retriever()
bm25_retriever.build_index(chunks)
# Retriever hybride
hybrid_retriever = HybridRetriever(
retrievers=[retriever, bm25_retriever],
fusion_strategy="reciprocal_rank_fusion"
)
pipeline = RAGPipeline(
retriever=hybrid_retriever,
llm=llm,
prompt_template=template
)
question = "Quels sont les points communs entre RAG et les moteurs de recherche classiques ?"
result = pipeline.answer(question)
print(result)
On peut également intégrer un reranker basé sur un Cross-Encoder pour réordonner les documents récupérés :
from rag_anything.rerankers import CrossEncoderReranker
reranker = CrossEncoderReranker(model_name="cross-encoder/ms-marco-MiniLM-L-6-v2")
pipeline = RAGPipeline(
retriever=hybrid_retriever,
reranker=reranker,
llm=llm,
prompt_template=template
)
Cette architecture modulaire permet d’expérimenter rapidement différentes combinaisons, ce qui est précieux pour le prompt engineering et l’optimisation de la pertinence.
Conseils pratiques et astuces de prompt engineering
Lors de ma formation en IA générative, j’ai constaté que la qualité du prompt et la sélection des documents contextuels sont déterminantes pour la performance d’un pipeline RAG. Voici quelques conseils issus de mon expérience avec RAG Anything :
- Limiter le nombre de documents contextuels : Injecter trop de contexte peut diluer la pertinence. Il vaut mieux sélectionner les 3 à 5 passages les plus pertinents, idéalement rerankés.
- Structurer le prompt : Utiliser des templates clairs, avec des instructions explicites (« Répondez uniquement à partir des extraits fournis ») améliore la factualité.
- Expérimenter le formatage : Ajouter des titres, des sources, ou des résumés dans le contexte peut aider le LLM à mieux structurer sa réponse.
- Utiliser le post-processing : RAG Anything permet d’ajouter des modules de post-traitement (paraphrase, vérification de factualité, etc.) pour affiner la réponse finale.
- Tester différents LLMs : La bibliothèque supporte plusieurs LLMs (OpenAI, HuggingFace, etc.), ce qui permet de comparer leur comportement sur le même pipeline.
Voici un exemple de prompt template structuré, avec sources et instructions :
from rag_anything.prompts import PromptTemplate
template = PromptTemplate(
"Vous êtes un expert en IA. Voici des extraits de documents, avec leur source :\n\n{context}\n\nEn vous appuyant uniquement sur ces extraits, répondez de façon concise à la question suivante :\n{question}\nRéponse (citez les sources si possible) :"
)
Et pour le post-processing, un module simple de paraphrase :
from rag_anything.postprocessors import ParaphrasePostProcessor
paraphraser = ParaphrasePostProcessor(model_name="Vamsi/T5_Paraphrase_Paws")
pipeline = RAGPipeline(
retriever=hybrid_retriever,
reranker=reranker,
llm=llm,
prompt_template=template,
postprocessors=[paraphraser]
)
En combinant ces techniques, il est possible d’atteindre un niveau de pertinence et de factualité très élevé, tout en gardant la main sur chaque étape du pipeline.
En conclusion, RAG Anything est une boîte à outils puissante pour tous ceux qui souhaitent explorer, personnaliser et optimiser des pipelines RAG. Sa modularité, sa compatibilité avec de nombreux modèles et frameworks, et sa philosophie « plug-and-play » en font un allié de choix pour le prompt engineering et l’expérimentation en IA générative. Que vous soyez chercheur, ingénieur, ou passionné, je vous encourage à explorer cette bibliothèque et à partager vos retours avec la communauté open source.